Microsoft Azure Purview – The best unified data governance solution for your organisation?
Do you struggle to deal with the volumes of data that sit across the business, either on multiple clouds or on-prem? Does storing data in multiple forms make tracking tougher? Most of us face this scenario because nobody really gives a holistic map of the data across your data landscape today. Azure Purview, a significant breakthrough service from a data management perspective tackles these issues with accuracy and efficiency.
Think about all the different data sources and data types that often exist in an organisation, from columnar data through to text files, BI reports, and many more. There is no easy way to understand or connect all these different data types without a lot of time consuming or manual work. And it is even harder to understand what operations are running against all that data.
Introducing, Azure Purview, a significant breakthrough service that will help you overcome these challenges. We typically [add] Azure Purview into your data hub infrastructure on Azure Cloud and connect it to systems across your estate.
How is Azure Purview different?
It all starts with the data. Organisations have many data assets, such as files, tables, BI reports, ML models, and many other things. And these things are often residing across on-prem, cloud and SaaS environments. You can connect your data systems to Azure Purview using an ever-growing set of included connectors. Purview can then scan those data sources, to extract a wide range of metadata—technical metadata, lineage, classification, and operational metadata. And most importantly, it does all this without moving the data itself. Scans from Purview operate serverlessly, so you only pay for what you use. For example, your data may be distributed across your Data hub, Azure Cloud Databases, AWS Redshift, Oracle PAAS, Oracle Cloud ERP, Workday, SAP, Salesforce, and Data Archival store. Purview allows you to get an end-to-end view of your data landscape, its lineage, consumption, and publication journey across all systems and processes in your enterprise.
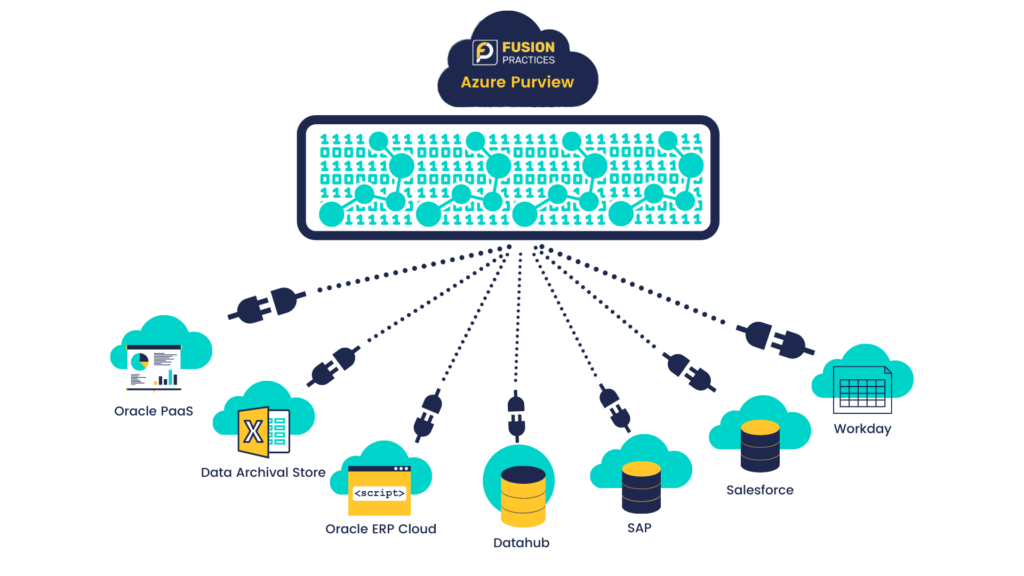
Azure Purview, using an ever-growing set of included connectors, can scan data sources to extract a wide range of metadata
Next, all the metadata found during scanning is then published to the Azure Purview data map. The map is an intelligent graph describing all the data across the data estate. Additionally, because the data map is exposed as Apache Atlas open APIs, one can programmatically push any metadata in Lineage from any data system, and this is a great way to expand the data map. Once the data map is in place, everyone in the organisation can go to the Azure Purview data catalogue experience and easily search and browse for data. In addition, chief data officers can get end-to-end insights across the data estate using the insights experiences, which are also provided.
Azure Purview works at solving for data discovery problems and enhances understanding, providing the foundations for effective data governance. Ultimately, the better companies understand the data they have, the more effectively they can use it across their organisation.
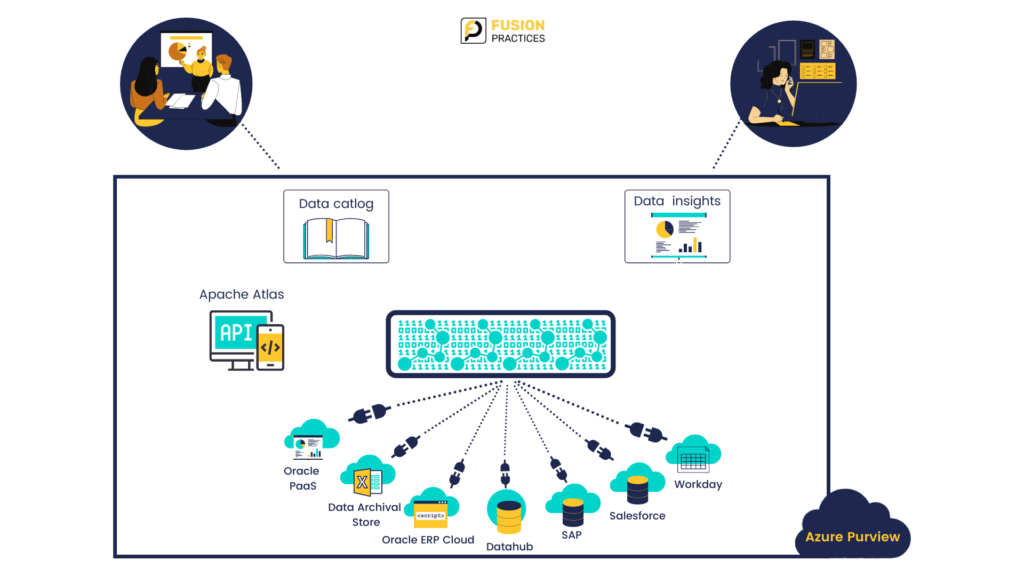
Purview gives a unified platform that automatically discovers and classifies data without having to move it. All the metadata discovered about the data is then indexed and brought together as a unified data map of your data estate.
Purview also provides rich user experiences, enabling data, producers, consumers, and stewards to easily collaborate. For example, business users and domain experts can interact with Purview’s business glossary to empower all users to easily understand the business context associated with the data in their organisation.
Most importantly, it solves a common conundrum—whether the data they are working with is the right or accurate. To solve this one needs to first understand where the data came from. Purview enables the user to easily track and visualise the lineage of the data across the data estate; so, one can easily see where data is moved and how it has been transformed.
Best-in-class holistic solution
Microsoft‘s collective experience— from the decades of work with Bing through to Azure Search for custom search and indexing— has been harnessed to build Purview and make it a reality. For instance, consider the case of the manufacturing company Howden, and the data classification technology that we have developed over the years for Microsoft Information Protection. All of this has provided us a mature foundation that we built from. Microsoft is also its own customer, and so the approach to scanning and mapping is highly inspired by what they do at Microsoft every day at exabyte scale to understand and govern their data estate. Further, they have also adopted some of the great innovations in the open-source community, such as Apache Atlas.
How will it make your workday better?
- User friendly navigation: On its home screen, Azure Purview, allows one to search for data using the Purview data catalogue. Under the search bar links to the knowledge centre and other common functions are present. Up on the left-hand bar is where one can easily navigate to additional experiences to register more data, set up scanning, get data insights and manage settings.
- Simple yet powerful Search: Assume that you start by searching for sales. It throws up suggestions and recommendations immediately even as we are entering the phrase. And when the search is executed, it finds matching business glossary terms, data assets, and returns the results intelligently based on relevance, using all the signals, derived from scanning and classifying the data as well as business context from the business glossary.
- Granular view: Moving ahead, select one of the search results, say sales order header. Here, it shows the operational metadata, and one can at a glance see, data contains sensitive information, such as credit card numbers and social security numbers. On the right side, it shows the hierarchy and where that dataset belongs inside of a table and schema and database and server. And from here if one needs to, they can then go ahead and open up the data, right in Power BI Desktop to visualise. Purview, like Azure Synapse, automatically creates that pivots file for Power BI users, so that data can be visualised automatically and straight from there.But what happens when we go and drill into the table’s information? What information is there?There is a lot of rich information available here. So, if we tour through the other tabs first with the Schema, you can see the column names from the table, their types, any classifications that have been applied, in this case, social security number, bank account, and even a custom classification for customer ID. And one thing to note here is that even though in this case, the column might make the data contained in these fields obvious, the system can still scan the content of the columns to verify the presence of sensitive information.The Lineage view: You often want to know where a piece of data came from as well as what data is derived from it. This helps assess at glance if the data comes from an authoritative source. Here one can view, all the Power BI reports that are ultimately based on the data from a particular table, as well as all the transformations that the data went through along the way.
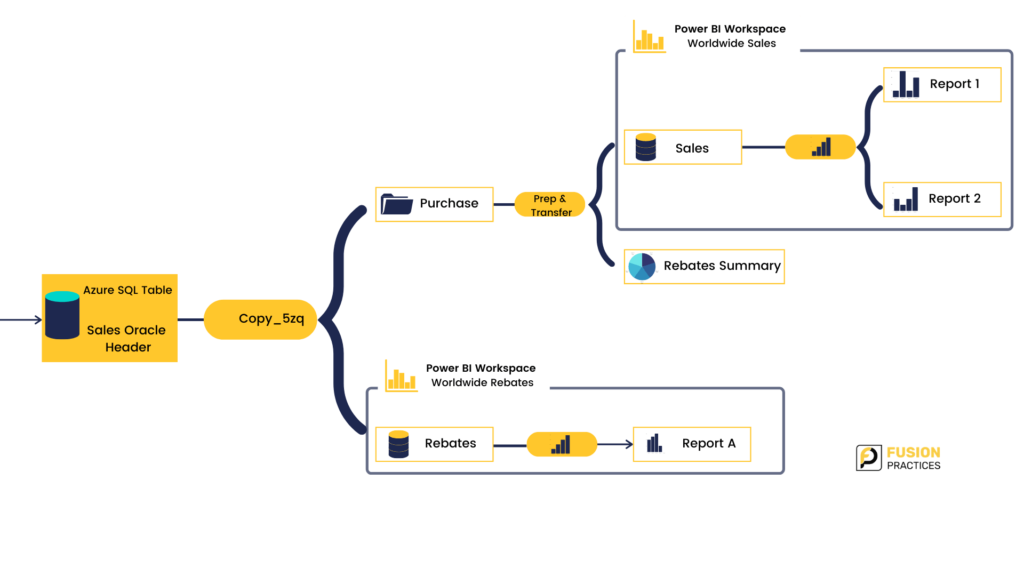
It is a lot more than just simple key pairs that are mapped out here. This is actually a pipeline view of the table through to the ETL steps, all the way down to the reports. Now these views would normally probably be drawn out manually with tools like Visio, for example, but it is being done automatically within Purview. Getting an end-to-end view like this can be really empowering when working with data because it is spanning data sources, operations on the data, as well as in this case, how that data is flowing into BI.
The Contacts tab identifies experts and owners of the data asset. And the Related tab can quickly browse all the other tables related to this one.
Also one of the best features of the lineage view is that it integrates well with Azure Datafactory and automatically captures lineage information when the pipeline is run. It then goes on to show the source data, sink data, and what operation went to form the sink dataset. With a simple click, it can directly go to Azure Datafactory pipeline where the actual transformations occured.
An added feature is that it not only works on structured data, but also for your unstructured and semi-structured data as well.
The Setup
What does it take to connect everything and get things like the classifications that we saw for sensitive information and everything kind of mapped up and working?
Purview makes this part of the process as easy as possible and enables this in just a few clicks.
An administrator, can click into the Sources area of Azure Purview. Here, all the data sources that Purview can automatically scan, a Storage account, Power BI, Hive Metastore and a few others can be seen.
Let us see how to connect a new data source to Purview. Click on the Register button and all the sources that are supported for automatic scanning are seen. There is a range of Azure sources. There is even both on-prem and multi-cloud sources such as Amazon S3, SQL Server, SAP, and Teradata.
The deep integrating capability of Purview with the data sources, enables it to extract the metadata that can securely flow to the Azure Purview instance. And for Azure sources, we made it really easy to register multiple sources in one step. On the other hand, with the Azure Multiple Sources option, it will find and register all the data sources automatically from a management group or a subscription.
Now it is likely that there are many data sources to connect. Purview allows you to organise them into collections and then visualise that as a tree view. This also allows to configure data scanning and classification settings at the root level of that collection, and those settings will then be automatically applied to everything underneath.
Once you have registered all of your data sources, the scans are going to automatically extract all the metadata that is required to power the search and the lineage experiences.
The data is going to continually change. So, the scans need to run periodically to ensure you have accurate and up-to-date understanding of your data.
What are the options if you want to start scanning your data?
There are a number of options available when the scanning is being configured. In the Management Centre, all the classifications that Purview can automatically detect are shown. It presently supports over 100 sensitive information types—from credit cards, account numbers, government IDs, location data, and much more. The same classification taxonomy of Microsoft 365 Information Protection or Data Loss Prevention is available in Azure Purview but now available across your other data sources as well.
Azure Purview allows you to define your own custom classification rules. For example, if we add TransactionID for new classification of attribute then you can define your own data pattern to identify a particular attribute to be a TransactionID during the scanning process. A similar approach can also be used for inventory number or a transaction ID or customer ID along with thresholds that you can set to reduce false positives during the scanning process. And once you have defined what you want to look for, you can configure scan rules.
You can choose file types you want to scan; you can even define your own file types if you have got them. Next, we will set up the classification rules that we want to run. These are the same hundred plus classifications we saw earlier, just grouped into categories. Custom classification rules can also be set here too just like for TransactionID. And finally, you can determine whether you want to run the scan recurringly or just one time. Data generally tend to change very frequently due to day-to-day operations or may be due to some transformation taking place. Hence, it is recommended to perform scheduled scans to incorporate all the changes that the data might have gone through.
Bird’s eye view of the data landscape
In addition to searching for a particular dataset in the catalogue, Purview also provides a bird’s eye view of your data landscape, and this is intended to help chief data officers quickly understand their data estate at large and gain key insights such as where sensitive data resides.
Insights area of Purview displays the bird’s eye view of the data estate. One can quickly see all the data which resides across a range of data sources. Scan Insights shows the number of successful, failed, and cancelled scans over time.
In the Glossary Insights section, changes made to the glossary over time can be quickly understood and one can assess how much coverage the glossary has over the data map. This view is extremely useful for compliance teams. Additionally, thanks to all the classification done previously, one can quickly determine where different kinds of sensitive data exist across the data map. You can also see which classification has been more frequently used to classify the datasets residing across multiple sources in an organisation.
Further it is also possible then to enable features such as proactive alerting in Purview. It is fully integrated with Azure Monitor and hence can set up alerts and additional views to monitor the health of your service and your scans.


