Azure Data Factory – Low code data driven platform in Azure Cloud
Agile and DevOps are not the only options CIOs have at their disposal to fuel faster application development. Enter low code development, a new tool on the block.
Low code development is boosting the cloud and data science industry by helping developers build applications that are robust and scalable.
Data engineering and migration continue to be challenging for many companies in the cloud sector as customisable solutions are hard to come by.
Developers–in addition to rapidly building software in coding sprints–are now increasingly using low-code development platforms to arrange application components, including data and logic, via a drag-and-drop interface. Think virtual Lego blocks that developers can move with a mouse and snap into their creations. The market for low code development tools will increase to 27.2 billion by 2022.[1]

Source: Gartner -Magic Quadrant for Enterprise Low-Code Application Platforms
Progressively, enterprise software development will be AI-supported, model-driven declarative application construction. On the other hand, vendors will remain relevant by focusing on underlying platforms and tools.
In Microsoft Azure, Data Hub is one of ETL based low code development applications used for data driven workflows in the cloud for orchestrating and automating data movement and data transformation. It is an orchestrator of services using instructions in the form of JSON. This tool is the backbone for building data hubs in Azure Cloud platform.
Advantages of Microsoft Azure Data Factory

Cost effective data integration with no infrastructure

Pay as per use

Scale as per need

Integrate expanded datasets from external organisations
- It is easy to integrate with Azure and other cloud services with embedded security. We have lately been integrating Azure Cloud Data Platforms to Oracle Cloud General Ledger, Workday, Oracle Cloud EPM, Murex, Moody’s, and ServiceNow.
- This tool runs the pure logic code developed by the developer, and resolves the issues of clusters and execution control from the developers and devops. Developers build resilient data pipelines using browser-based designer, in an accessible visual environment, and let ADF handle the complexities of Spark execution.
- Mapping data flows include built-in data transformations to address common ETL activities such as join, aggregate, pivot, unpivot, split, lookup, and sort data. Developers can use an expression builder to customise their ETL solution.
- Azure Data Factory also provides live insights on the data moving through Azure Data Factory pipelines. These insights include metrics such as null counts, value distributions, standard deviations, minimum and maximum length values, row counts and more.
- Debug options can be used for analysing the data flow making the ETL process simpler.
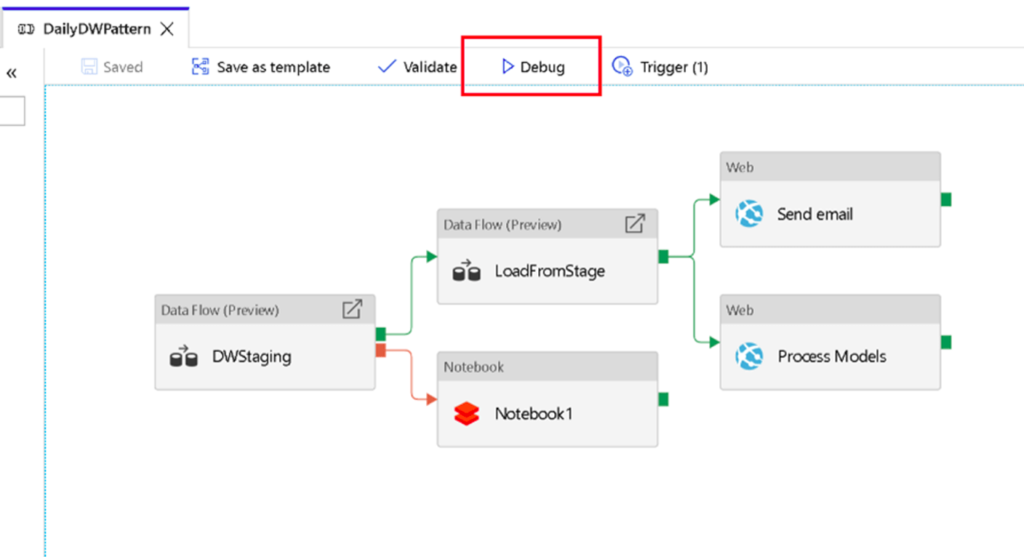
- The CI/CD feature enables usage by multiple developers using git configuration and allows for a hassle free deployment.
- Azure Data Factory ensures loss-less data migration from on-prem database to cloud services.

Transform data with speed and scalability using the Apache Spark engine in Azure Databricks. Use Azure Data Share to accept new datasets into your analytics environment, then use Data Factory to integrate them into your pipelines to prepare, transform, and enrich your data to generate insights.
So, building ETL process in cloud without infrastructure, using Spark as a background tool and Azure GUI for development results in seamless data migration. In addition, post data fine-tuning, businesses can also use analytics to gain insights. Data warehousing and data populating from APIs or CSV files and analytics assessment is easier, scalable and faster.
Fusion Practices is both a Microsoft and an Oracle Partner. Our expertise in both the platforms has enabled us to build several reusable components in Azure Data Factory and Azure Functions to integrate them with Oracle Cloud ERP and Oracle Cloud EPM. This enables our clients to leverage their data platform investments in Azure cloud for seamless integrations with Oracle Fusion Financials and Oracle Cloud HCM.
[1] https://www.businesswire.com/news/home/20180116006370/en/27.2-Billion-Global-Low-Code-Development-Platform-Market
Author: Ashok Venkat is an Azure Data Specialist at Fusion Practices.


